")
According to a Pendo report, up to 80% of features in an average software product go unused. In 2018 alone, 600 public companies spent nearly $30 billion on such features – and the trend hasn’t changed much. One common reason behind this is overengineering, adding complexity in the name of reliability, future scalability, or simply “just in case.” This trap catches not only startups but sometimes industry leaders and even entire countries. Apple, for instance, once launched a Retina display with a resolution beyond what the human eye can perceive. Meanwhile, the UK’s ambitious National Health Service digitalisation programme collapsed in scandal in 2011 after nearly ten years of development and £10 billion in sunk costs.
But where is the line between flexibility and excess – and is overengineering always a bad thing?
In this interview, Vasilij, an Engineering Manager at Bamboo Agile, shares his insights on what overengineering is, how it can be avoided, and how to maintain a balance between simplicity and complexity in development.
Defining overengineering
How do you define overengineering, and why is it a concern in software development?
– Overengineering happens when a solution becomes more complex than what is necessary to meet the actual requirements. It can involve adding extra features, layers of abstraction, or components that don’t provide significant value to the project. It’s easy to get distracted by the idea of covering every possible edge case or making the solution “perfect”. But these efforts can often be wasted if they don’t align with the real needs of the business.
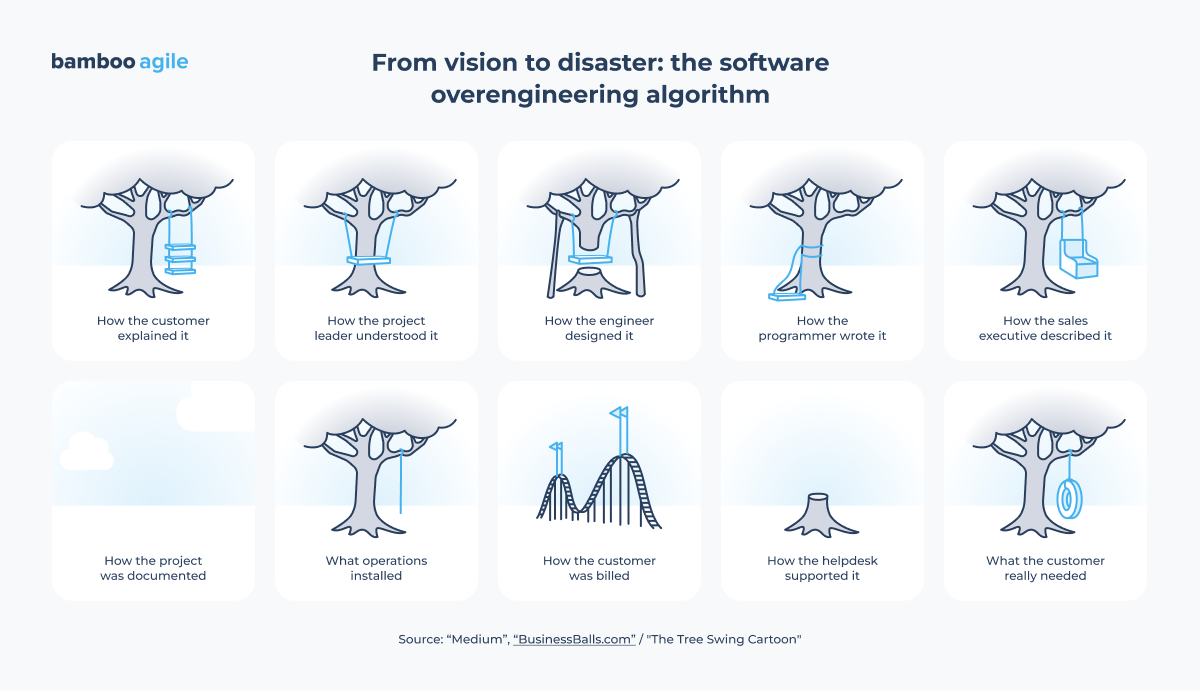
What are the main causes of overengineering, and how can we identify when it’s happening?
– It often happens when there’s uncertainty about the project’s scope or requirements. If the goals aren’t clearly defined, developers might try to build solutions that cover every possible scenario, even those that aren’t needed right now or in the near future.
Another key cause is when teams focus too much on perfection. This includes trying to make the system more scalable than is necessary. It’s important to remember that overengineering is usually driven by good intentions – we want to create something robust and adaptable – but it can end up being counterproductive if the business needs don’t require that level of complexity.
The concept of overengineering is quite controversial. It’s about how different people understand the balance of what should be done upfront, what should be done later, and what should evolve as the product develops.
In 2019, a team of researchers from the US, UK, Sweden, and Italy concluded that overengineering is more of a psychological issue than a technological one. Based on a survey of 307 developers, the authors identified three components contributing to a tendency toward overengineering: cognitive, emotional, and behavioural. According to their findings, developers with intuitive thinking are more likely to add features based on gut feeling rather than data. At the same time, “rationalists” often try to account for every possible scenario from the outset. Emotional attachment to a project amplifies both types of excess. As for experience, it can go either way – reinforcing outdated habits in some while helping others better assess potential risks.

How, in your opinion, should we approach this balance?
– I lean more towards an evolutionary approach. Essentially, if the system can operate simply, let it operate simply. That doesn’t mean it should be rudimentary and impossible to scale, though.
In reality, I think the belief that something can’t be changed later unless you do it perfectly from the start is wrong. Anything can be changed; it’s actually easier to adapt things as you go. This may seem at odds with some managerial principles, but in software development, sometimes, it’s beneficial to interpret client requirements flexibly rather than rigidly adhering to them. Often, a task can be approached in a broader or simpler way.
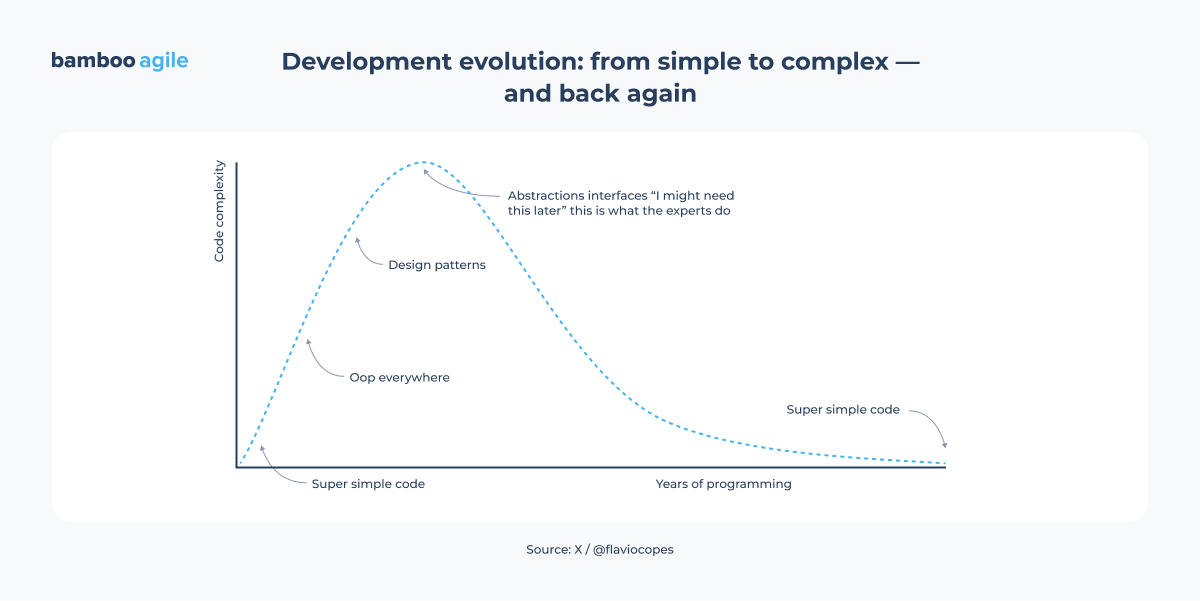
For example, there are a lot of different UI widgets. They may look very different at first glance. But in general, there is a development hierarchy behind them. Sometimes it’s just a simple bar, sometimes it’s a bar divided into four sections, or there are some numbers, percentages, or other elements. In theory, this could be just one component that adapts to the settings.
One developer’s approach might be to create a bunch of different widgets for every possible scenario, each one unique with its own specific features. Alternatively, you could create a single component where different settings determine its appearance and functionality.
The point is, if you focus on something general and experiment with it, it will be easier to work with constantly changing client requirements later on.
Feedback changes; clients test things out, and later they might want different colors or additional features. It’s much easier to adapt if you went with a single, customizable component. In this case, discussions like “this wasn’t in the requirements” become less relevant. A well-structured component can be easily adjusted, so you don’t have to build anything from scratch.
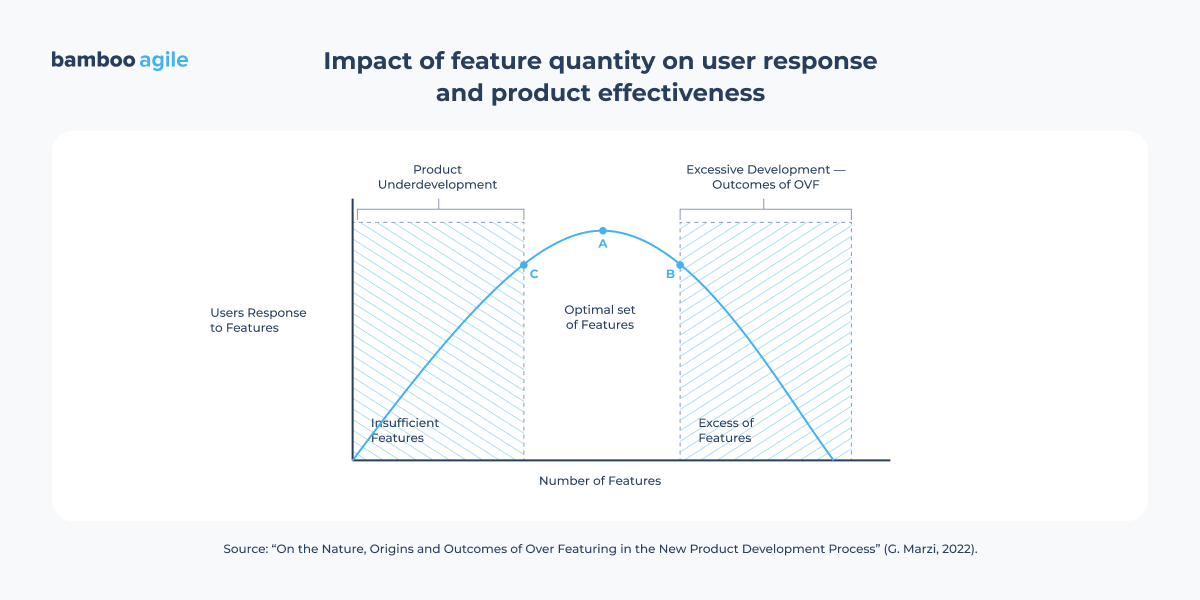
Here, you’re designing a component with just enough flexibility to handle foreseeable adjustments. You’re not trying to cover every scenario, but rather anticipating likely, reasonable changes that might arise.
Of course, there’s also a need for a balance so the budget doesn’t balloon, but very often, adding a small detail early on can save you a lot of work later when something inevitably changes.
So, you’re saying it’s better to think ahead, even to add features that allow future customization and scalability?
– Yes, exactly. I think the idea that something can’t be changed is pushed too strongly by developers who want to create overly abstract solutions from the start. You can start simpler, but you need to know where to draw the line. It’s about finding the right balance – making it flexible enough to adapt to change but not so complex that it blows the budget from the start. Then, you can accommodate client feedback without major headaches.
A similar line of thinking comes from American software engineer and author Robert C. Martin (“Uncle Bob”), who advocates for the principle of provable necessity. At its core is the idea that abstractions should only be introduced when there’s a clear, objectively proven need. Many of them, he argues, emerge naturally through testing or in response to real changes in the codebase. Rather than anticipating every edge case upfront, Martin suggests starting simple and evolving the design through refactoring. As he puts it: “You’re probably already in the overengineering zone if you spend more time designing than implementing.”
But how do you recognize when a system is just “simple and adaptable” versus when it’s actually holding a business back? Sometimes, what seems like a logical setup at first can turn into a major constraint later.
– I can give you an example. It’s a case where we moved away from overengineering on the client’s side in favor of a modern solution that better fit both their industry and business growth strategy. We didn’t push too hard – the transition happened naturally.
One of our clients had (and still has) a business built on a Scandinavian e-commerce platform. It’s essentially their regional alternative to Shopify – highly customized and tailored specifically to Scandinavian markets. In the early stages, it probably made sense for them to use it while growing locally.
But when we took an outside look at the platform, it was immediately clear that it was outdated, with deep-rooted legacy constraints. Everything required custom development – there were no ready-made solutions, even for integrations. At the time, they had just one integration – with a local Scandinavian service, used for logistics and limited CRM functions. But the CRM was barely functional – it only served as a frontend display for products, with no built-in order management.
Our first reaction was, “This doesn’t make much sense. Why not Shopify? It has built-in features, ready-made apps, and stable integrations.”
Of course, they’d have a hard time switching to Shopify right away.
But when they started expanding internationally into markets like the US and Canada, they quickly ran into problems. Their legacy setup struggled with regional pricing, local tax rules, and integrations with non-Scandinavian delivery providers. Everything, again, required custom development, making it both costly and inefficient.
With Shopify, all they had to do was upload their products, and it just worked.
So, we picked a free Shopify theme, spent about a hundred hours customizing it to match their brand, and launched. The experience was so smooth that they eventually migrated most of their international operations to Shopify while still maintaining their original platform for local markets.
But that was a period of, I don’t know, two or three years of working with them. In the end, it was about choosing a solution that met their needs quickly. It’s all written, you don’t need to reinvent the wheel, just handle some integration work, maybe a small worker here and there to add data somewhere else, like Klaviyo or something.
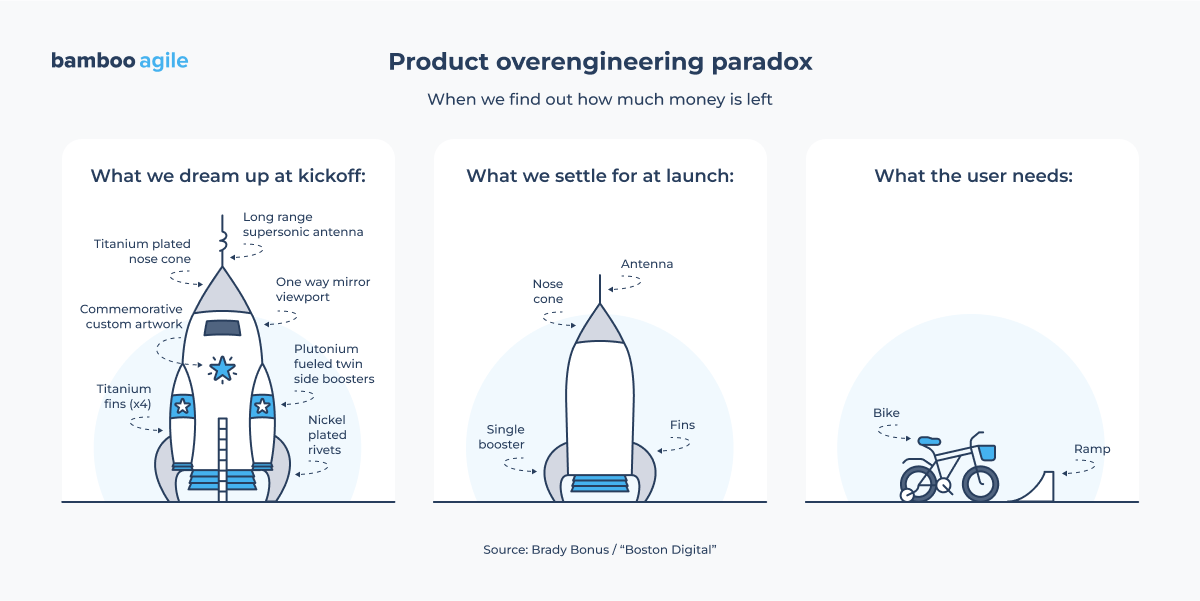
Real-world examples of overengineering and lessons learnt
Have you previously faced any specific architectural decisions that didn’t go as planned?
– Well, there was one example that caused some controversy among us. The microservices architecture is going out of fashion. We all know it’s necessary in large-scale projects, you can’t avoid it there. But in cases of MVP (Minimal Viable Product) projects, at once, in my opinion, the wrong path.
Sometimes, we tried to skip the MVP stage and went straight to developing a product ready for sale. But the MVP stage is essential – it’s there to figure out what needs to be done to make the product market-ready. Going straight to a scalable architecture in the beginning can only make things more complex.
It reminds me of the Amazon Prime Video case. A couple of years ago, their team developed a prototype of distributed microservices architecture for video quality monitoring using AWS Step Functions and Lambda. But they soon ran into scalability issues and high infrastructure costs – the system hit a performance ceiling at just 5% of the expected load, and frequent calls to S3 to pass video frames between services turned out to be too expensive. They ended up rethinking the approach and merged the components into a single monolithic service running on Amazon EC2 and ECS. That cut their infrastructure costs by over 90% and significantly improved scalability. It’s pretty surprising to see something like this come from a team within a company that’s one of the biggest advocates of microservices in the industry.
Of course, there’s been plenty of debate in the community about whether this example truly counts as a clear return to monoliths, and such decisions are never one-size-fits-all. But we’ve also faced similar dilemmas in our own work, so I think it’s food for thought.
Yes, that Amazon case is really interesting and truly debatable. But thinking back to it, are you saying that you see a monolithic approach as the more reasonable choice in situations like that?
– I wouldn’t make such a broad claim.
I know of a company that created one of the first online payment systems in Poland. They started with microservices, just two of them. It was a simple system, and they didn’t even think they needed more. It worked fine for them within the scope of one country.
So, I’d say it really depends on the specific goals and context of the project.
British-American software architect and author Martin Fowler is one of the most prominent experts cautioning against microservice architecture in early-stage projects or small systems. While he recognises their value in complex architectures, he believes that adopting microservices too early leads to unnecessary complexity: teams either build things that won’t be needed in the end (violating the YAGNI principle) or struggle to manage a distributed system due to a lack of operational maturity.
I see your point. That said, have you ever faced situations where, on the contrary, opting for a simpler approach led to challenges?
– Actually, I’d say most problems come from overcomplicating things. However, we did have a case where a seemingly simple solution led to unexpected challenges.
The client wanted to integrate an open-source component written in basic JavaScript. His request was to adapt it, turn it into a PWA, and add React on top.
Soon, we hit a wall with this solution – customising its appearance was tricky, and wrapping a framework around it was very challenging. It wasn’t a small library performing a single function; it was a whole system with lots of interactions and complexities.
We started with a proof of concept, where we outlined the pros and cons of continuing and what could happen. During this process, we found that making it into a PWA – even in its most basic form – wasn’t achievable. The goal seemed out of reach.
There were too many overheads just to add PWA functionality. We evaluated it and realised it wasn’t going to work, especially after the client stated that the system should be viable for at least five years. If we built it with native JavaScript, finding developers to support it later would be impossible.
Ultimately, we used the library just as a reference for implementing some graphic interactions, but we didn’t directly rely on it for the core functionality.
Looking back, I highly recommend carefully choosing libraries and checking their tech constraints. Always compare them to your long-term goals. Approaching the task with a PoC can be also a smart move – it would help you spot issues early.
Best industry practices
Many industry leaders have developed their own ways of avoiding overengineering – from Netflix’s automated resilience testing and Meta’s “Move fast with stable infrastructure” to Google’s rules where “a new developer should understand your code within one sprint.” Do you explore such practices? Which ones are applicable in your context, and which, in your view, aren’t fit for regular companies and teams?
– I try to study them, yes. There’s a reason these companies are seen as industry leaders – they crystallize the kind of approaches that help them move forward more effectively than most. And help the whole industry at the same time.
You mentioned Meta’s more recent principle, “Move fast with stable infrastructure,” but I’d actually go back to the earlier – and probably more famous – version: “Move fast and break things.” You know, even though Meta eventually revised it, I still think it works well for early-stage startups as a way to test ideas with real users as quickly as possible.
As for Google’s approach, with its focus on code readability and self-documentation, – I think it fits better in large-scale projects where lots of people are involved.
That said, the approach I personally like the most is what we saw at early Twitter when the evolution of solutions happened as an organic response to real user needs and the real-time challenges that come from the system’s live conditions.
")
Cultural and organizational factors
Let’s shift the perspective a bit. There’s a discussion about whether certain cultural or organizational environments are more prone to overengineering. Have you noticed any national, cultural, or regional traits – whether in engineering culture or management style – that contribute to this tendency?
– Yes, there are some observations — more from the behaviour of clients than foreign colleagues. However, these peculiarities, of course, influence the course of development.
In my experience, clients from Scandinavian countries tend to be actively involved in product decisions. I’ve also noticed that they’re often the ones to propose and readily agree to the simplest possible solutions.
American customers, from what I’ve seen, also tend to prefer simple solutions, but they usually don’t go as deep into the decision-making process. Instead, they delegate most of the implementation steps to the development team.
As for clients from the UK, I’d say they’re actually the most inclined toward overly complex solutions. That said, on the upside, this often comes with very detailed specifications, which gives the project team a clear view of potential optimisations even before development begins.
To sum up. Looking back at the decisions you’ve made, do you think there’s a specific criterion you use when deciding on an approach?
– It’s not an exact science, but generally, if the business is growing, if we see progress within a certain period – a year, a year and a half – and there’s good communication between development and the business side, it indicates that the right system was chosen.
I tend to favor simple or ready-made solutions because they require fewer resources and can be tested quickly. If something doesn’t fit, we adjust. It’s about finding the right balance between flexibility and simplicity.
Key takeaways
There are a lot to think about, so let’s highlight the main insights mentioned in our interview.
Overengineering isn’t always a mistake, but it’s almost always a reason to reassess. At Bamboo Agile, we help teams objectively examine their architecture and uncover bottlenecks before they turn into real problems. If you’re looking for a fresh perspective on your system, considering a technical audit, or exploring Fractional CTO services, don’t hesitate to book a consultation with our experts.





