Introduction
“Do we start with a monolithic architecture or do we jump straight to microservices?” is a question not enough startups ask themselves. That is because most think the answer’s obvious: monolith is the default choice for budding companies. But is it really that simple?
When a piece of software is built to scale, adopting a microservices architecture becomes only a matter of time. In that case, another question arises: why go through the costly migration process, when you can start with microservices development instead?
To answer these inquiries, one would have to first explore the pros and cons of both approaches to architecture. So we’ll do exactly that.
Monolith vs Microservices: Know the Difference
Let’s establish what monolith and microservices architectures are.
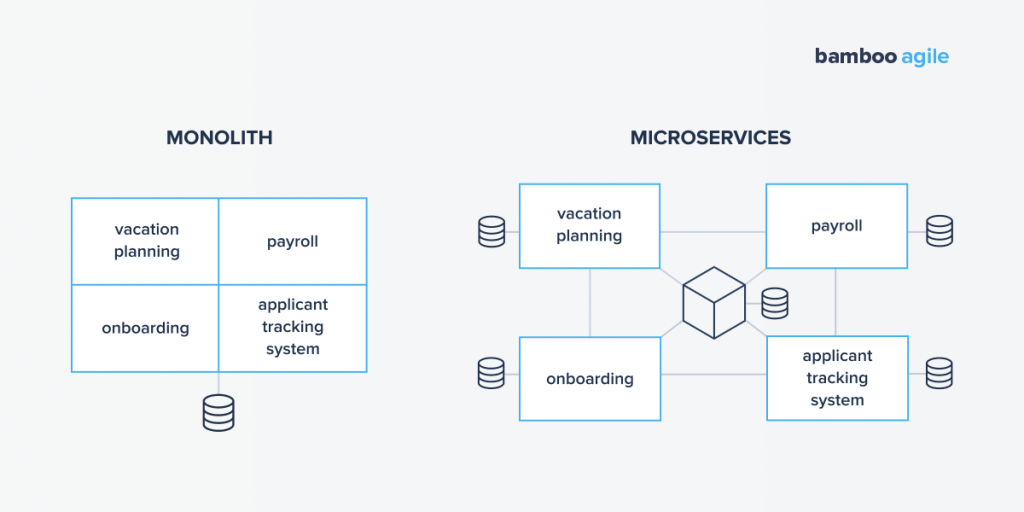
Monolithic architecture is considered a traditional way of building software. A monolithic app is a single indivisible unit, which usually comprises a server-side application, a client-side interface, and a database. Here, all the functions are managed and served in one place.
Monolithic apps tend to have one large code base. And whenever developers want to update a certain aspect of the application, they have to modify the entire software. So, because of the app’s unified nature, every minor change affects the whole stack.
Microservices architecture is a whole nother beast. While a monolithic app is a single inseparable unit, a microservices architecture breaks it down into smaller independent elements. Each of them carries a specific application function separately. This means that all the app services have their own logic and databases.
Such architecture allows developers to make changes to certain parts of the application without having to update the whole app. Also, while the entire functionality is split into independently deployable modules, they communicate with each other using APIs.
Monolith Advantages
- Fast performance during the initial stages. One of the benefits monolith architecture has is high initial speed. That’s because monolith applications use local calls instead of API calls across the entire network. However, one must keep in mind that as the number of users increases and the software itself expands, its speed will fall accordingly.
- Easy to manage. It’s a lot easier to set up logging, monitoring, testing, and deploying a single solution than a number of separate apps.
- Cheaper. Continuing the previous point, all those tasks are considerably less expensive to perform with only one application involved.
- Fewer cross-cutting problems during the initial stages. There are far fewer cross-cutting risks associated with fresh monolithic software. Really, developers only need to worry about one application’s logging, caching, etc. Mind you, the risk of internal conflicts grows as the solution scales – especially when multiple developers are working on it.
Monolith Disadvantages
- Slow boot-ups. Since all business logic is contained in one place, the time it takes to start and restart the system increases.
- Poor stability. Due to the nature of the architecture, an error in one module can crash the entire system.
- Vulnerability. Similarly to the previous point, if a single component is attacked, the whole system is in danger because of its units’ mutual proximity.
- Hard to scale. Monoliths may be easier to manage when the application is small, but as it expands and employs new functionality, the close-knit nature of the app becomes a problem. Simply put, maintenance and independent scaling of components become near-impossible, as the code grows more and more convoluted.
- Difficult to understand. This one is directly related to the previous point. When the script is a tangled mess, it becomes very hard to navigate. This is especially bad for onboarding: the oldies may know where everything is, but new team members will have to spend lots of time getting used to the app’s spaghetti code.
Microservices Advantages
- Effective performance. If organized well, microservices-based solutions can outperform monolithic ones, especially when more complex software is involved.
- Superior organization. Each microservice has its own specific job and does not directly depend on other components. This makes managing elements of a microservices application a lot simpler.
- Decoupled services. Decoupled services can be easily reconfigured to serve the purposes of different apps (serving both web clients and public API, for example). This also allows for fast independent delivery of individual units within a large integrated system.
- Error-proof. The microservice architecture allows developers to establish a hard boundary between certain parts of the system. This helps prevent unwanted entanglements – namely, connecting parts that shouldn’t be connected. It also prevents excessively tight couplings between the parts that should be linked.
- Improved scalability. Thanks to better organization and clear borders between various elements of the app, microservices software is very convenient to expand and update. Every component can be upgraded separately, so there’s no need to restart the entire software.
- Greater stability. If one component of a microservices solution breaks, the rest of it will continue to work as normal. This results in significantly reduced – in some cases, completely eliminated – downtimes.
- Security. The relative isolation of various units means that cyber attacks and data breaches will be harder to carry out on a system-wide scale.
Microservices Disadvantages
- Operational Overhead. Microservices are often deployed on their own containers or virtual machines, which means lots of VM wrangling. On the other hand, these tasks can be automated with container fleet management tools.
- Higher initial cost. Microservices architectures need secure and sufficient hosting infrastructures, as well as skilled development teams to maintain the services. All this means more upfront spending than a monolith usually requires. That said, this downside is usually mitigated in the long run, as scaling a monolith is generally more expensive.
- Cross-cutting. You may not anticipate it when designing a new microservices architecture, but you’re likely to encounter many cross-cutting concerns during the building stage. For that reason, microservices testing involves checking all separate modules for cross-cutting risks.
- Debugging. Tracing the source of an error can become a challenge when an app consists of a variety of units, with each having its own set of logs.
So which is it?
Now that we’ve defined what a monolithic architecture is, what a microservices architecture is, and what their strengths and weaknesses are, we can decide which one suits your startup best.
Start with a monolith if…
- Your team is at the founding stage. It’s very difficult to tackle a high-overhead microservices architecture with a team of only 2-5 people.
- You’re making an unproven product or a proof of concept. If you’re building a product based on a novel idea, it’s likely to evolve or pivot at some point. Monolith works better for that purpose, since it supports rapid iteration. Proof of concept development follows the same rules: even if you end up discarding the end product, the ultimate goal of the process is to simply learn as much as possible as quickly as possible.
- You’re new to microservices development. Learning on the go may work in some instances, but risking your time and money at such an early stage may not be the best choice, considering how complex microservices can be.
Start with microservices if…
- You plan to scale. Having small dedicated teams for different services makes scaling and organizing app development significantly easier. If you begin with microservices, your developers will get used to working in small separate teams from the start. This will also eliminate the need for possible migration later down the line.
- A part of your software needs to be super efficient. Say, your business does intensive processing of petabytes of logs. That service would have to be built in a very efficient language (in C++, for example). Meanwhile, the general user dashboard can be written using something like Ruby on Rails.
- You need quick independent service delivery. Microservices are your best bet if you require quick isolated service delivery. But keep in mind that it will take some time for the service delivery gains to really kick in, if your development team is small.
What next?
If you’ve made the decision to use a microservices architecture from the start, then you’re pretty much set for the long run.
One opportunity that’s worth considering, however, is getting help from a third-party development company in case your team is either too small or too inexperienced to consistently handle microservices development. Outsourcing system maintenance or even the development process itself could be more cost-effective than headhunting and employing full-time in-house specialists.
But what if you’ve decided that a monolith architecture is more appropriate for your current project? If it’s something that won’t need to majorly expand, you’re good to go. However, if your software is meant to scale in the future and modernize your monolith, migration to microservices is something you ought to think about.
Let’s look at each option in a little more detail.
Building a Microservices Architecture by Using an API Gateway
Approaches to Retrieving Microservice Data
Say, you want to create a native mobile client for a shopping app. That shopping application needs a product page, which displays lots of information: product name, price, and description; customer reviews, number of items in the shopping cart, shipping options, etc.
If the solution is monolithic, the mobile client will retrieve the necessary data with a REST call to the app (GET https://api.company.com/productdetails/productId). That request will be routed to one of the many identical application instances by a load balancer. Then the app will query different database tables and return the response to the client.
If the app uses microservices, however, each piece of data is owned by a different microservice (i.e. customer reviews belong to the review service, shipping options belong to the shipping service, etc.). Because of that, there are multiple ways to access the needed information:
1.Make requests to each of the microservices directly. Here, each microservice has a public endpoint (https://serviceName.api.company.name) which is mapped to its load balancer, and the mobile client makes a request to each of the services via those endpoints. However, this approach is rather inefficient.
Firstly, the client will need to make numerous requests just to load one product page. This isn’t a huge problem when an app is simple. But in more complex solutions, the number of requests can go well into the hundreds. Public Internet and mobile networks are very likely to struggle with processing this amount of information. Plus, it seriously complicates the client code.
Secondly, not all microservices will have web-friendly protocols (for example, Thrift binary RPC and the AMQP messaging protocol are more suitable for internal use). The app should use protocols like HTTP and WebSocket outside the firewall.
And finally, it makes refactoring microservices a lot more difficult.
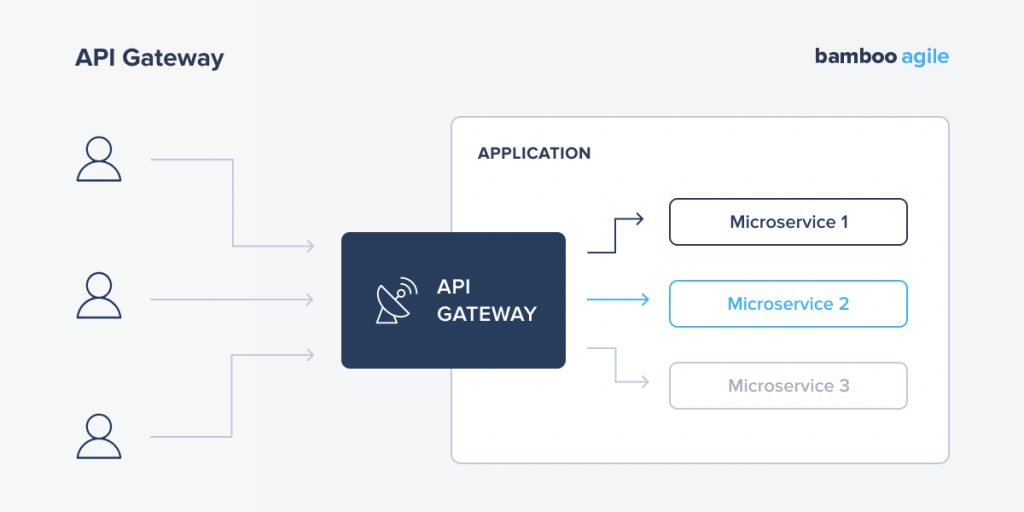
2.Use an API gateway. A much more common and useful approach. An API gateway is a server that acts as a single entry point into the system and performs multiple functions, including authentication, monitoring, load balancing, caching, and others.
Every client request will go through the API gateway before being routed to the appropriate microservice. API gateways can also aggregate the results of requests to multiple microservices and translate web-unfriendly protocols.
Of course, it also has its drawbacks. An API gateway needs to be developed, deployed, and consistently managed. The gateway also needs to be updated to expose each microservice’s endpoints, so the process of updating it has to be as lightweight as possible.
Now let’s look at the peculiarities of API gateway implementation.
API Gateway Features
Scalability and Performance
Good performance and scalability are crucial to any API gateway. Because of that, API gateways are often built on platforms that support asynchronous non-blocking I/O. There are many technologies that can help implement a scalable API gateway: there’s JVM that supports NIO-based frameworks (Spring Reactor, Netty, Vertx), there’s Node.js based on Chrome’s JavaScript engine, and there’s NGINX Plus, which is perfect for high-performance projects.
Reactive Programming Approach
API gateways tend to perform independent requests concurrently to minimize response times. However, sometimes, there are dependencies between requests. Because of that, API composition code using the traditional asynchronous callback approach is very likely to get tangled and difficult to understand. Using a declarative style of code with a reactive approach alleviates that problem. Future in Scala, CompletableFuture in Java 8, and Promise in JavaScript are just some of the reactive abstractions available on the market.
Service Discovery Mechanism
Your API gateway has to know the IP address and port of each microservice it communicates with. Infrastructure services like message brokers usually have a static location that can be specified through OS environment variables. On the other hand, determining the location of an application service is often a challenge, since it is dynamic. That’s why the API gateway needs a service discovery mechanism: either Server-Side Discovery or Client-Side Discovery. Note that if your system uses the latter, the API gateway must be able to query the Service Registry.
Partial Failure Handling
Partial failure is something that arises when one service calls another, and the other service is responding slowly or is unavailable. How your API gateway handles that failure depends on the scenario. For example, if the recommendation service in an online store is unresponsive with some product details, the API should return the ones that are available to the customer, as they can still be useful. The recommendations can also be left empty or show a hardwired top ten list. API can also return cached data in case the pricing service is unresponsive (since product prices change infrequently), and show an error message if the product information service is unavailable.
Inter-process Service Communication
There are two styles of inter-process communication in microservices. The first one is an asynchronous, messaging-based mechanism. It can be implemented through message brokers such as JMS and AMQP, or use a brokerless direct communication service such as Zeromq. The second type of inter-process communication is synchronous (HTTP, Thrift). Systems often use both styles, so your API gateway will need to support them equally well.
Let’s have a more in-depth look at the issue.
As was already mentioned, inter-process communication in microservices comes in two types:
- synchronous – the client expects an immediate response from the service and can even block while it waits;
- asynchronous – the response doesn’t have to be immediate (or isn’t needed at all) and the client doesn’t block while waiting for it.
However, there’s one more important distinction:
- one‑to‑one communication – each client request is processed by one service instance;
- one‑to‑many communication – each request is processed by several service instances.
In turn, there are different types of one-to-one and one-to-many interactions. These are the kinds of one-to-one interactions:
- request/response;
- notification (a.k.a. a one-way request);
- request/asynchronous response.
And the kinds of one-to-many interactions are:
- publish/subscribe;
- publish/asynchronous responses.
Every service usually uses a combination of different interaction styles. Some services can function with a single IPC mechanism, but most require multiple.
Migration from Monolith to Microservices
For many growing companies, migration from a monolithic architecture to microservices is part of a broader enterprise application modernization strategy. There are two common strategies for this process.
The so-called Big Bang rewrite is just as radical as it sounds. It basically involves rewriting the app for microservices from scratch. The straightforwardness of this method may sound appealing to some, but it’s a very risky approach that’s likely to end in failure.
A far safer strategy is the Strangler Application method. Its name comes from the strangler vine that grows around a tree to reach the sunlight above the thick forest canopy. When the tree dies, only a tree-shaped vine remains.
This app modernization strategy works exactly like that. The new microservices application is gradually built around the monolithic app, until the latter isn’t needed anymore. The microservices-based application runs in conjunction with the monolith. So, as the microservices solution gains more and more functionality, the monolithic application will shrink. Eventually the monolith either disappears or becomes just another microservice.
Let’s have a brief run-through of a typical process. A typical migration process can be described in 8 major steps.
- Identifying Local Components. Software engineers identify all local components and determine which of them are best for migrating: the most frequently used components, the components that have the fewest dependencies on others, the components that perform too slowly.
- Flattening and Refactoring Components. This involves checking for duplicated data, checking all data formats; verifying data types, data accuracy, and data units; identifying outliers, and dealing with missing fields and values.
- Identifying Component Dependencies. This is done using a static analysis of the source code to search for calls between various libraries and data types. In addition, there are several dynamic-analysis tools that can create automated maps between components.
- Identifying Component Groups. Based on the identified dependencies, the system architect organizes the components into cohesive groups that can become either macro- or microservices.
- Creating an API for User Interface. To maximize the final system’s scalability, the API should be able to handle all the data objects in the system, be stateless and versioned, as well as have backwards compatibility. REST API is the most common choice, but it’s not always necessary.
- Migrating Component Groups to Macroservices. This is an optional step that helps simplify migration to microservices, especially when the overall application is constantly changing.
- Migrating Macroservices/Component Groups to Microservices. Self-explanatory. Here, it’s good to note that separating the components and functions of a monolithic system into macroservices first provides insight into how these components can be further divided into microservices.
- Microservices Testing and Deployment. Before deployment, microservices have to undergo thorough integration testing. When it’s clear that there are no connections to the old datastore left in the remaining monolithic code, the service is ready to be deployed.
Of course, this is a very brief description of the process. Of course, this is a very brief description of the process. One of the questions organizations frequently ask before starting such a project is how much does modernization cost. The answer depends on factors such as application complexity, technical debt, integration requirements, and the chosen migration strategy.
For a more detailed example of migrating a monolith app to microservices, check out this case study with step-by-step migration from monolith to microservices process description.
Microservices Beginner Tips
Setting up microservices doesn’t have to be difficult or costly. If you’re a startup that wants to employ a microservices architecture with minimal stress involved, these tips will help you cut corners both in terms of convenience and pricing.
- Use industry-standard tools.
Stick to what’s tried-and-true, unless using your custom tools is absolutely necessary. Plus, your whole application (that is, all your microservices) is better off stored in a single repository with a single CD deployment pipeline.
- Use one Kubernetes cluster.
Hosting your app in a single Kubernetes cluster will streamline your security model. Authenticate at the gateway, treat internal connections as trusted, and run the cluster on one virtual machine. You won’t need more than one until you require greater performance or reliability.
- Avoid replicas.
Don’t replicate any of your microservices, unless you need heightened performance or plain redundancy.
- Use one database server.
While having a separate database for each microservice is good practice, you can host all of these databases on one database server. After all, maintaining a single server is far easier than managing one for each microservice.
- Do manual testing.
If you’re just starting out, don’t bother with automated testing – you will need it, but only eventually. For the time being, put some effort into writing a script that can quickly boot the application to a testable state (with database fixtures and whatnot). This will make manual testing much more efficient.
- Automate deployments.
Have an automated CD pipeline ready from day one of going to production. In a way, this is the most important part of your entire app: getting consistent feedback from customers is the lifeblood of any startup.
You may ask, “Doesn’t using a single repository and a single deployment pipeline defeat the point of microservices?” To a degree, yes, but only during the initial development phase.
You’ll be able to easily extract your microservices to separate code repositories later on. When you feel like the time for that has come, use the meta tool. It will allow your independent repositories to act as a single repository, which will greatly simplify development.
Conclusion
It’s easy to see the benefits of both monolith and microservices architectures. Both work amazingly in their respective contexts and are equally worthy of consideration. Simply follow the guidelines set up in this article and find out which architecture will bring the best out of your application.
In case your company wants to go in for microservices development, but isn’t sure where to begin, feel free to contact our specialists for a free consultation. Whether you want to develop an app from scratch, migrate a monolith solution to microservices, or get help in deciding which course of action would be the most suitable for your project, the experts of Bamboo Agile will be happy to lend a hand.





