
A failing software project rarely announces its collapse. Deadlines slip, of course, yet real warnings can stay quiet. Instead of clear proof, teams call work almost done. Conversations lose their weight. Meanwhile, quick fixes pile up and masquerade as progress. At that point, failure does not come from one bad call; rather, the project drifts there, one step at a time.
Based on the 2026 research by PM World Journal, the IT project success rate continues to experience stagnation, moving from roughly 29% a decade ago to just 31% today. At the same time, 50% of projects are described as challenged, and 19% are deemed as failures.
Comparative evolution of IT project success rates (2015-2025)
| Metric | 2015-2017 | 2020-2024 | Variance |
| Success (on time, budget, scope) | 29% | 31% | +2% |
| Challenged (late, over budget, etc.) | 52% | 50% | -2% |
| Failure (cancelled/never used) | 19% | 19% | 0% |
Source: Comparative research on IT project failure rates: A 2025 longitudinal update, PM World Journal, 2026
So, how do you save a project on the brink of disaster? We asked this question to Alexey Shinkarev, Engineering Manager at Bamboo Agile. Below, he shares his real-life project-based insights on the matter.

Alexey Shinkarev
Alexey is an engineering manager with a backend background in Node.js and TypeScript. He has led cross‑functional teams of up to 15 people, delivering production systems that include a payments platform, LMS, and telehealth application. At Bamboo Group OÜ, Alexey takes full ownership from pre‑development and architecture through MVP delivery. He pairs hands‑on development with engineering leadership.
Signs that your software project is failing
We all know missed deadlines are a bad sign. Yet, software projects usually drift rather than fail in a single moment. And by the time anyone admits something is wrong, the warnings have often been visible for a while. Based on your experience, what quieter, more subtle indicators tell you a project is secretly heading toward disaster?
In my opinion, one of the most alarming signs on any project happens when transparency starts to fade. Team members say a task is done or almost done, but cannot offer the necessary detail. Communication breaks down – people lose initiative, and no one asks hard questions. Or the team constantly relies on quick fixes to patch holes, and that becomes the new normal.
Now that you talked about the communication crisis and constant patching, it sounds like these two can arrive together. Could you walk me through the messiest project rescue you have personally managed where both played their role, and the situation was more serious than it looked?
There was one of the projects where we entered a phase of major changes and worked directly with the client’s CTO. At that time, our input on technical problems and possible solutions did not get much traction, and our role felt closer to pure execution.
Here, I can say that besides communication, the major problem was the bugs that our team inherited from the previous engineering squad. The client’s management pushed for new features without fully accounting for unfinished work in the existing functionality. Only after someone on the client side gained trust from both their management and our team did communication start to flow better, and project dynamics improve.
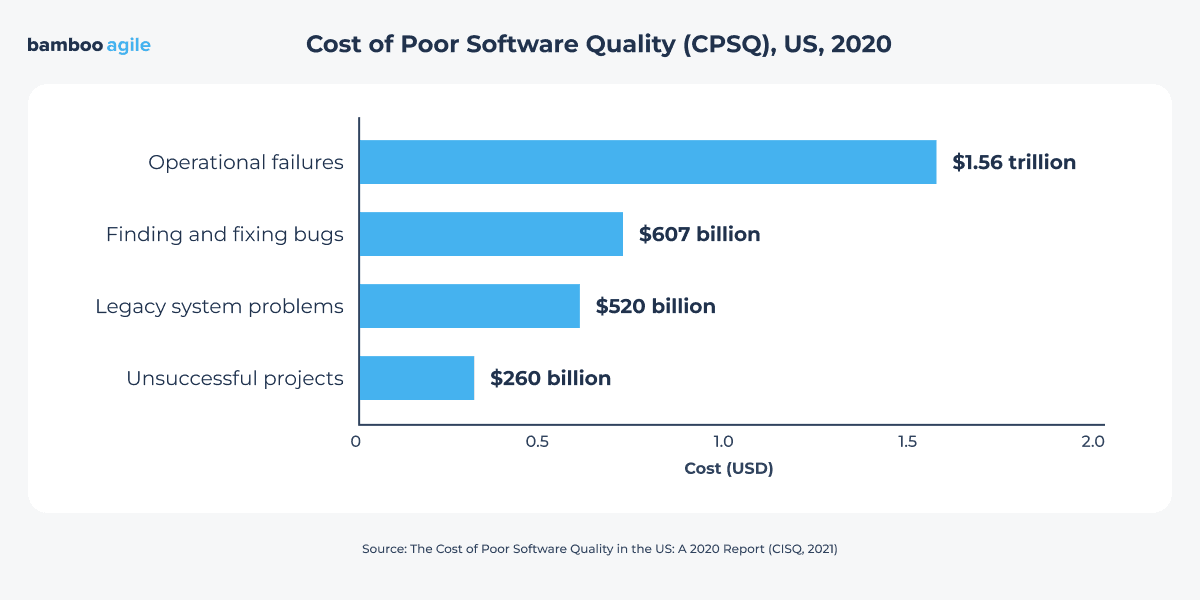
According to The Cost of Poor Software Quality in the US: A 2020 Report by CIQC, companies in the United States alone spent over $607 billion on finding and fixing bugs in their software in one year.
How to handle project takeovers
Since you mentioned bugs that remained from the previous team, let me ask you the following. When you take over a project, the old team often still holds the keys, or the client fires them outright. What is your advice for managing that awkward transition period, given the additional pressure of unfinished technical debt and stalled trust?
To begin with, try to remove any emotional baggage. Make clear to every member of the new development team that criticizing past decisions or the previous team does not help – especially before you have proven your own team’s performance. Organize knowledge transfer, access, and documentation. If you need to work alongside the old team for a while, agree on communication channels and divide areas of responsibility.
Should you rescue or rebuild your software project?
Let us say the handover is done, and you finally have access to everything. When you first open the repo for the troubled project, what is the first red flag in the codebase that tells you this was not just messy code, but a fundamentally broken architecture?
First things first, you need to see if such a project has a defined structure. Because if it does not, this means you cannot tell where the business logic lives, as well as where the database operations happen or where the integrations sit. As a result, everything becomes intertwined. A change in one place then breaks something else in a completely unexpected location.
For AI-powered projects, the failure rate is significantly higher. RAND estimates that 80% of artificial intelligence projects fall through. Among the reasons for this are overconfidence in AI, using it to solve simple tasks, too few data engineers in the team, lack of domain understanding, and more.
Teams often want to rewrite everything instead of working around the old codebase. How do you distinguish between code that is truly unsalvageable and code that is just unfamiliar to avoid unnecessary overhead during the rescue phase?
In cases like this, I try to consider several factors. First, you need to see whether the team can adequately reproduce the functionality. Next, I analyze if we can isolate the problematic part and what architectural constraints affect new features. If the code works, we can isolate and improve it – then the work is worth doing.

What is the actual math behind deciding to patch, refactor, or trigger a full re-architecture?
Ideally, determine the client’s total cost of ownership (TCO) in two scenarios, namely stabilization with gradual refactoring versus a complete rewrite. Start by estimating both costs and considering the risks for each option. From there, if stabilization plus refactoring costs less than sixty percent of a full rewrite, then saving the existing code makes sense in theory.
However, two factors can override that rule. On the one hand, the client may plan a large number of changes. On the other hand, the architecture may lack scalability, or the stack may no longer have support. In either case, a rewrite becomes unavoidable anyway.
I see, the stack that loses support is one of the override factors. And at what point do you think the tech stack itself becomes the biggest issue?
It is all fairly standard, to be honest. One, the stack lacks community support. Two, it fails to meet modern requirements like security and load handling. Three, it demands specialists who are either unavailable or extremely expensive. Four, it does not allow for scaling.
But still, you also have internal constraints to work around, like the assessment, TCO calculation, or stack evaluation. Do you think the client always understands this? And did you ever have to say ‘No’ to save the project from further issues?
One common request is to add new functionality to an area that feels unstable – or, frankly, where the system is close to collapse. I often had to delay new feature development in various ways until the old part of the system became stable. This may naturally cause some frustration, but it is still better than cleaning up a much bigger mess later.
Where to start when taking over a troubled project
So, the client is aligned, new feature work is on hold, and you can finally focus on the system itself. How do you help the client prioritize which inherited issues to fix first (e.g. technical debt, performance, security, etc)?
We look at security and stability of critical functionality as the top concern. Performance comes right after that. And throughout the whole process, we work on technical debt in small, parallel increments – so we never pause feature work or wait for a big cleanup phase.
And how do you approach messy, spaghetti code without causing more instability?
Instead of trying to throw out or rewrite everything at once, begin by adding tests to your most critical problem areas. Then isolate pieces of the functionality. From there, refactor those pieces little by little and gradually expand what the code can do.
Speaking of performance, what is your method of fixing critical bugs and bottlenecks left by the previous team without causing new regressions?
You will want to start by getting a feel for how the development process is organized – testing, code reviews, CI/CD, and monitoring all play a part. If something in this process breaks, take the time to fix it before rushing out a release.
Of course, each of these steps could fill a whole discussion on its own.
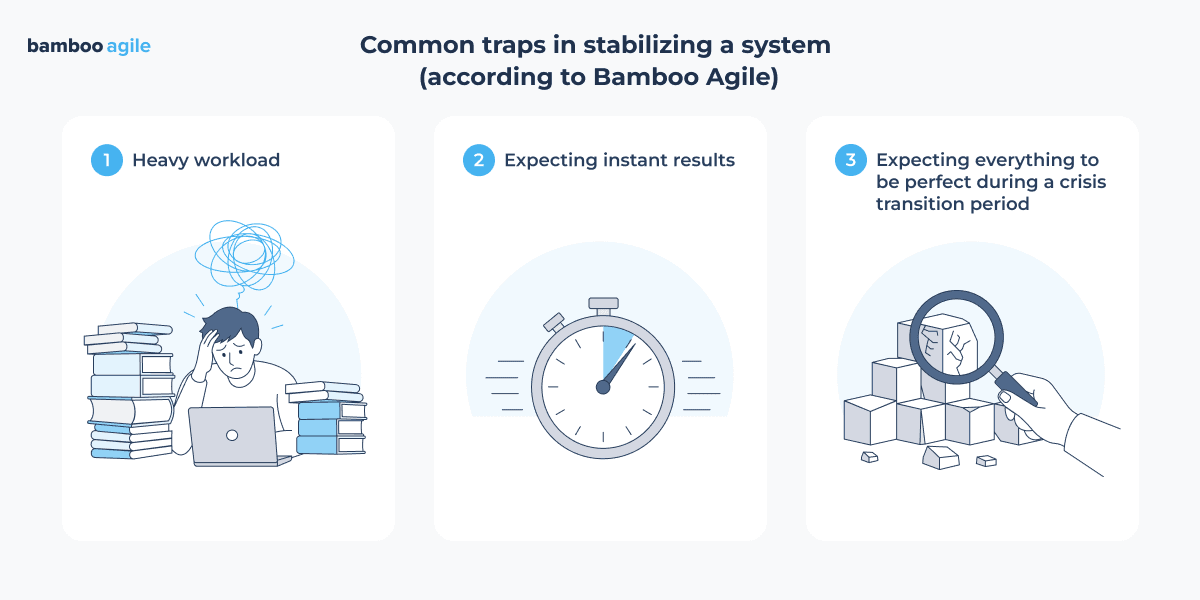
Well, even if the process is organized well, clients may struggle with stabilizing a system. Are there common traps they should be aware of?
I would highlight three major issues.
- Heavy workload on the team due to urgent tasks that needed to be done yesterday.
That makes prioritization essential. - Expecting instant results. You may want to start with a detailed step-by-step plan, and accept that real progress usually takes time.
- Expecting everything to be perfect during a crisis transition period. The focus should be on predictability and stability, not on perfection.
Getting a software project back on track for the long term
Once you achieve that stability and move past the immediate crisis, how do you then design your processes to keep that stability over time? What specific processes (e.g., automated testing, CI/CD, documentation standards) do you put in place?
I focus on keeping the system stable over the long run with a few core practices.
- Write tests for important features
- Run a full CI/CD pipeline
- Review every pull request thoroughly
- Put monitoring and logging in place everywhere.
Rescue missions often breed a ‘hero culture’ where one or two devs work 80-hour weeks to save the day. How do you transition a project from ’emergency mode’ back to ‘sustainable development’?
Hero culture does not come just from long hours. There’s also a certain chaos in how the team works. To fix that, put a planning process in place. If you work in sprints, get everything organized and run the usual Scrum events. Alongside that, calculate your team’s real capacity, and limit how many tasks stay in development at any one time.
Some of the most notable failures of an IT project is Target’s pulling out of its Canadian expansion. The retail giant accumulated $2.5 billion in losses. One of the main reasons for the unsuccessful expansion is named as data quality.
How to choose the right software project rescue team
We have discussed a lot of moving parts today – the process itself, architecture, team dynamics, and client expectations. But before any of these can happen, the client should make the most important decision, which is who to trust with the rescue. From your experience, how can a client tell whether a team genuinely knows how to rescue a troubled project?
From what I have seen, watch out for any team that immediately wants to throw out the old code and rebuild everything from scratch, especially if they start by trashing the previous developers. A good software project rescue team acts differently. They stay open about timelines, risks, and real-world constraints. Also, real experts talk honestly about trade-offs you might have to accept. They give you a concrete rescue plan with a transparent way to measure progress. If they cannot show you how to judge success step by step, they are likely selling confidence, not competence.
If you could summarize Bamboo Agile’s approach to rescuing projects in a few principles, what would they be?
This is my take:
- First measure, then act. Our team diagnoses and plans before writing any code.
- Stabilize the product and the processes first. Only then do we scale or add features.
- Change gradually. No chaotic rewrites or ground-up refactoring.
- Stay transparent and ready to compromise.
- Invest in the future architecture from day one.
- Long-term sustainability beats short-term wins.
- Give the business back control over its product. That is the whole point.
Key takeaways
If we take into account Alexey’s advice, these will be the best practices for tech project success:
If rescuing a troubled project feels harder than it should, it may be worth taking a closer look at how your team measures progress, prioritizes fixes, and communicates trade-offs. If you want to go deeper into this topic in the context of your own project, feel free to reach out.





