
Introduction
Node.js is used by about 2% of all websites. Node is the foundation of some of the most popular online platforms, such as Twitter, Netflix, Spotify, Github, and more.
Choosing the best database for a Node.js project is one of the first things you need to consider before you start development. Node.js typically supports all database types, regardless of whether they’re SQL or NoSQL. Nevertheless, the choice of a database must be made based on the complexity and purposes of your application. In this article, we will take a closer look at SQL and NoSQL databases, as well as at their practical examples.
SQL and NoSQL Databases
All computer calculations are related to data processing. They can be structured and unstructured. The former are placed in databases, where their description is stored, along with the information. You can often come across the terms “SQL” and “NoSQL” when talking about databases.
SQL is a processing technique that is used for processing relational and non-relational (NoSQL) databases.
The term “relational” comes from algebra. In databases, this means that relational database data is stored in the form of tables and rows. Non-relational databases store information in collections of JSON documents.
Relational databases use SQL, which stands for “Structured Query Language”. The structure of such databases allows you to link information from different tables using foreign keys (or indexes), which are used to uniquely identify any atomic piece of data in each table. Other tables can refer to this foreign key to create a relationship between data parts and the parts pointed to by this foreign key.
Why do we need non-relational databases? Their main advantage is a high level of security and the ability to bypass hardware restrictions.
Now let’s take a look at the differences and similarities between SQL and NoSQL databases.
Language
Imagine a city where everyone speaks the same language. This language is used in all forms of communication and all business processes are built on it. The inhabitants of this city understand each other and explore the world around them only through this language. If the language suddenly changes in one place, everyone else will be confused.
Now imagine another city, where everybody speaks different languages at home. Everyone interacts with the world in different ways, there is no “universal” way of understanding and no sustainable organization of communication. If one changes something, it will not affect anyone else.
This example helps illustrate one of the main differences between SQL (relational) and NoSQL (non-relational) databases.
Relational databases use a structured query language to process and manipulate data. On the one hand, this is quite convenient: SQL is one of the most versatile and commonly used language options, so it is a safe choice. Also, it’s suitable for complex queries. On the other hand, there are certain limitations with this language. Before you start working with SQL, you need to use predefined schemas to define the data structure. In addition, all data must have the same structure. It’s like the first example said: a change in structure can result in complications and destroy the entire system.
In contrast, non-relational databases have flexible schemas for unstructured data. It can be stored in different ways: in columns, documents, graphs, or as a key-value store.
This flexibility allows the following:
- You can create documents without defining their structure in advance;
- Each document can have its own unique structure;
- The syntax may differ in different databases;
- You can add new fields in the process of work.
SQL uses a universal structured query language to define and manipulate data. This imposes certain restrictions: before starting processing, the data must be placed inside tables and described.
Scalability
In most cases, SQL databases can be scaled vertically, which means that it is possible to increase the load on each individual server, increasing the power of the CPU, RAM, and disk. But NoSQL databases can be scaled horizontally. It means that the load is distributed by splitting data or adding more servers. One is like adding more floors to a building, and the other’s like adding more buildings to a neighbourhood. The latter allows the system to become larger and more powerful. That is why NoSQL is usually chosen for large or frequently changing databases.
Structure and Data Type
Relational databases store structured data, which usually represents objects in the real world. For example, it can be information about a person or about the contents of a shopping cart. That data is grouped in tables, the format of which has been set during the store’s design stage.
Non-relational databases are structured differently. For example, document-oriented databases store information in the form of hierarchical data structures. Here we can have objects with an arbitrary set of attributes. What would be split into several interconnected tables in a relational database can be stored in a non-relational database as a single integral entity.
Requests
Regardless of the license, RDBMS use SQL standards, so you can get data from them using the SQL language.
NoSQL databases do not use a common query format, so each NoSQL solution uses its own query system.
Support
Relational DBMSs have a long history behind them. They are very popular and offer both free and paid solutions. It’s much easier to find the answer to a relational system problem than to a problem with a NoSQL system, especially if the solution is complex in its nature.
SQL and NoSQL Databases Comparison
| SQL | NoSQL | |
| Query language | Structured | Non-declarative |
| Type | Table-based | Document-based, key-value pairs, graph |
| Schema | Predefined | Dynamic |
| Scalability | Vertical | Horizontal |
| Examples | MySQL, PostgreSQL, SQLite | MongoDB, Redis, Apache Cassandra |
| Data storage | Most suitable for the hierarchical model | Suitable for the hierarchical in key-value pair model |
| Open-source | A mix of commercial and open-source | Open-source |
| Hardware | Specialized | Commodity |
| Storage type | SAN, RAID, etc. | Standard HDDs, JBOD |
SQL Databases for Node.js – Comparison

General
MySQL
MySQL is one of the most widely used database management systems today. It accounts for 16.65% of all database usage, surpassed only by Oracle at 30.2%.
This system is used to work with fairly large amounts of information. However, MySQL is ideal for both small and large projects. An important characteristic of the system is that it is free of charge.
See how we used MySQL for Node.js in a variety of projects, including an LMS, a digital wallet, a marketing platform, a CS:GO rankings app, and an AI-powered EdTech solution.
PostgreSQL
PostgreSQL is a popular free object-relational database management system. PostgreSQL is based on the SQL language and supports numerous features, such as:
- Asynchronous replication;
- User-defined types;
- Nested transactions;
- Multi-version concurrency control;
- Referential integrity for foreign keys;
- Table inheritance;
- And more.
We have used PostgreSQL alongside Node.js to build a smart telehealth application. Check out this case study to learn more.
SQLite
The database is easily embeddable into applications. Since this system is based on files, it provides a fairly wide range of tools for working with it, compared to network DBMS. When working with this DBMS, requests are made directly to files (where data is stored), instead of ports and sockets in the network DBMS. SQLite is also very fast and powerful thanks to the serving library technologies.
Data Types
MySQL
MySQL supports the following data types:
- TINYINT: very small whole integer;
- SMALLINT: small whole integer;
- MEDIUMINT: medium-sized whole integer;
- INT: normal-sized whole integer;
- BIGINT: a large whole integer;
- FLOAT: single-precision signed floating-point number;
- DOUBLE, DOUBLE PRECISION, REAL: signed double-precision floating-point number;
- DECIMAL, NUMERIC: signed floating-point number;
- DATE: date;
- DATETIME: a combination of date and time;
- TIMESTAMP: stamp of time;
- TIME: time;
- YEAR: a year in YY or YYYY format;
- CHAR: a fixed-size string, right-padded with spaces to the maximum length;
- VARCHAR: variable length string;
- TINYBLOB, TINYTEXT: binary or text data with a maximum length of 255 characters;
- BLOB, TEXT: binary or text data with a maximum length of 65535 characters;
- MEDIUMBLOB, MEDIUMTEXT: text or binary data;
- LONGBLOB, LONGTEXT: text or binary maximum data of 4294967295 characters;
- ENUM: enumeration;
- SET: sets.
PostgreSQL
The supported field types in PostgreSQL are quite different, but they allow you to write the exact same data:
- bigint: signed 8-byte integer;
- bigserial: an automatically growing 8-byte integer;
- bit: fixed-length binary string;
- bit varying: a binary string of varying length;
- boolean: flag;
- box: a rectangle on a plane;
- byte: binary data;
- character varying: a fixed-length symbol string;
- character: a symbol string of varying length;
- cidr: IPv4 or IPv6 network address;
- circle: a circle on a plane;
- date: date in the calendar;
- double precision: floating-point number of double precision;
- inet: Internet IPv4 or IPv6 address;
- integer: signed 4-byte integer;
- interval: time interval;
- line: an infinite straight line on a plane;
- lseg: line segment;
- macaddr: MAC address;
- money: monetary value;
- path: geometric path on the plane;
- point: geometric point on a plane;
- polygon: a polygon on a plane;
- real: single-precision floating-point number;
- smallint: two-byte integer;
- serial: automatically incremented four-bit integer;
- text: variable length pattern string;
- time: time of day;
- timestamp: date and time;
- tsquery: text search query;
- tsvector: text search document;
- uuid: unique identifier;
- xml: XML data.
SQLite
Storage classes:
- NULL – The value is a NULL value;
- INTEGER – The value is a signed integer stored in 1, 2, 3, 4, 6, or 8 bytes, depending on the magnitude of the value;
- REAL – The value is a floating-point value that is stored as an 8-byte IEEE floating-point number;
- TEXT – The value is a text string stored using the database encoding (UTF-8, UTF-16BE, or UTF-16LE);
- BLOB – A value is a block of data that is stored exactly as it was entered.
Merge type:
- TEXT – This column stores all data using the storage classes NULL, TEXT, or BLOB;
- NUMERIC – This column can contain values using all five storage classes;
- INTEGER – Functions the same as a column with a NUMERIC affinity, with an exception in the CAST expression;
- REAL – Behaves like a column with a NUMERIC affinity, except that it casts integer values to floating-point representation;
- NONE – A column with an affinity of NONE doesn’t favour one storage class over another, and no attempt is made to force data from one storage class to another.
Data Storage Features
MySQL
MySQL is a relational database where various engines are used to store data in tables. However, the process of working with engines is hidden in the system itself. The engine affects neither the syntax of requests nor their execution. The main supported engines are MyISAM, InnoDB, MEMORY, and Berkeley DB. They differ from each other in how data is written to disk, as well as in their retrieval methods.
PostgreSQL
PostgreSQL is an object-relational database that runs on only one engine – a storage engine. All tables are represented as objects and can be inherited; all actions with tables are performed using objectively oriented functions. All data is stored on disk, in specially sorted files, but the structure of these files and the records in them vary greatly.
SQLite
SQLite is an embedded database. The word “embedded” means that SQLite does not use the client-server paradigm. In other words, the SQLite engine is not a separately working process the program interacts with, but a library the program is linked with – the engine becomes an integral part of the program. Thus, the function calls (API) of the SQLite library are used as an exchange protocol. This approach reduces overhead, lowers response time, and simplifies the program. SQLite stores the entire database (including definitions, tables, indices, and data) in a single standard file on the computer the program is running on.
SQL Standard Support
MySQL
MySQL doesn’t support all the new features of the SQL standard. The developers chose this path of development to keep MySQL easy to use. The company does try to meet the standards, but not at the expense of simplicity. If a feature can improve usability, then developers can implement it as an extension regardless of the standard.
PostgreSQL
PostgreSQL is an open-source project. It is developed by a team of enthusiasts, and the developers try to comply with the SQL standard as much as possible, while implementing all the newest standards. But all this leads to the loss of simplicity. PostgreSQL is very complex, and because of this, it is not as popular as MySQL.
SQLite
SQLite strives to live by the “minimal but complete” principle. It does not support some complex features, but its functionality corresponds to SQL 92 in many aspects. And it introduces some of its own features, which are very convenient, albeit non-standard.
The following features are not supported:
- RIGHT and FULL OUTER JOIN. Only LEFT OUTER JOIN is implemented;
- ALTER TABLE is partially implemented. Only RENAME TABLE and ADD COLUMN are available;
- Partial trigger support. Only FOR EACH ROW triggers are available;
- Recording in VIEWS. In SQLite, VIEWS are read-only. Partially bypassed through triggers;
- Due to the implementation of the database as a single file and the departure from the client-server concept, the GRANT and REVOKE capabilities are not used;
- Foreign keys are disabled by default. This is for backward compatibility.
Performance
MySQL
In most cases, an InnoDB table is used to organize work with a database in MySQL. This table is a B-tree with indices. Indices allow you to get data out of the disk very quickly, meaning fewer disk operations. But scanning a tree requires finding two indices, which is already slow.
PostgreSQL
All PostgreSQL table header information is in RAM. You cannot create a table that is outside the memory. The table records are sorted by index, so you can retrieve them very quickly. For more convenience, you can apply multiple indices to the same table.
In general, PostgreSQL is faster, with the exception of operations involving the use of primary keys.
SQLite
As in MySQL, indices in SQLite are built on the basis of the B-tree algorithm. What makes it unique is that SQLite is perfectly suitable for small databases. As the database grows, the memory requirements also increase when using SQLite. There is little to no optimization for SQLite performance.
To improve the performance of the database with indices, it’s better to avoid:
- using them on small tables;
- using them on tables with frequent, large batch updates or inserts;
- using them for columns with a big amount of NULL values.
Popularity
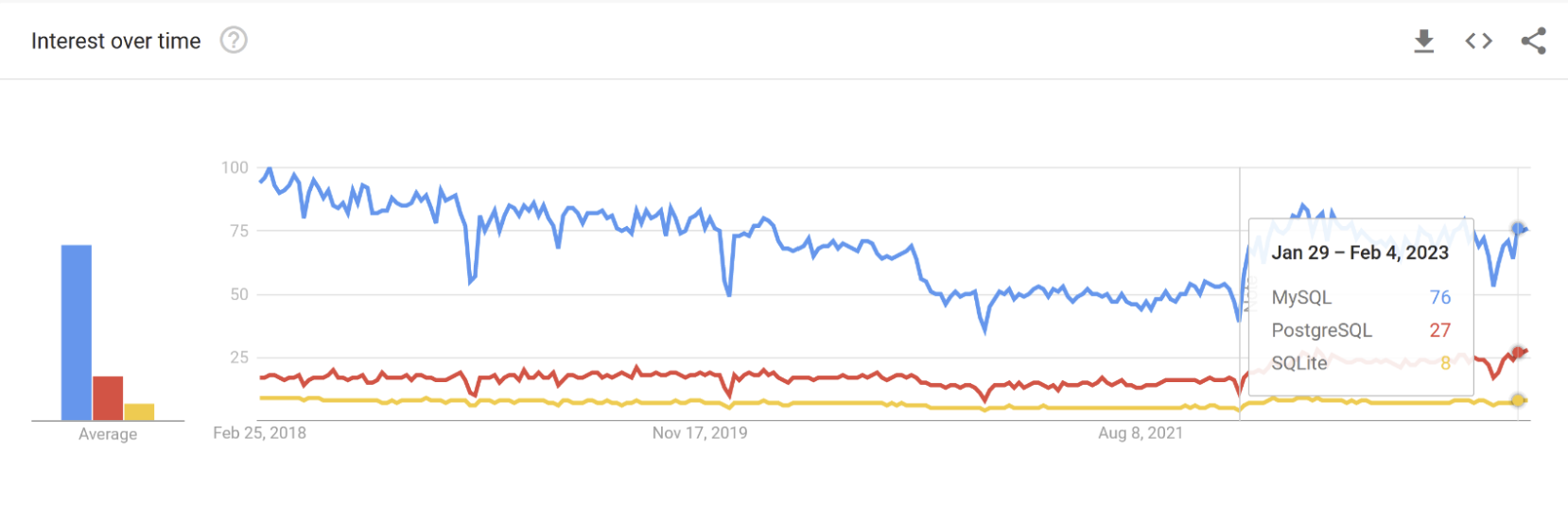
In the past year, MySQL was the most popular database of the ones mentioned above. PostgreSQL was in second place and SQLite took the last one.
Choosing the best SQL database for Node.js
| Criteria | MySQL | PostgreSQL | SQLite |
| Data types | TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT, FLOAT, DOUBLE, DOUBLE PRECISION, REAL, DECIMAL, NUMERIC, DATE, DATETIME, TIMESTAMP, TIME, YEAR, CHAR, VARCHAR, TINYBLOB, TINYTEXT, BLOB, TEXT, MEDIUMBLOB, MEDIUMTEXT, LONGBLOB, LONGTEXT, ENUM, SET. | bigint, bigserial, bit, bit varying, boolean, box, byte, character varying, character, cidr, circle, date, double precision, inet, integer, interval, line, lseg, macaddr, money, path, point, polygon, real, smallint, serial, text, time, timestamp, tsquery, tsvector, uuid, xml. | Storage classes: NULL, INTEGER, REAL, TEXT, BLOB. Merge type: TEXT, NUMERIC, INTEGER, REAL, NONE. |
| Data storage features | Various engines that are hidden in the system are used to store data in tables. They do not affect the syntax of requests. They differ from each other in the way the data is written on the disk. | Only a storage engine is used. | All data is stored on disk, in specially sorted files with different structures. |
| SQL standard support | Doesn’t support all the new features. If needed, they can be implemented as an extension. | Developers try to comply with the SQL standard as much as possible and implement all the newest standards. | In many aspects, it corresponds to SQL 92. The following features are not supported: RIGHT and FULL OUTER JOIN. Only LEFT OUTER JOIN is implemented; ALTER TABLE is partially implemented. Only RENAME TABLE and ADD COLUMN are available; Partial trigger support. Only FOR EACH ROW triggers are available; Recording in VIEWS. They are read-only. Partially bypassed through triggers; GRANT and REVOKE capabilities are not used; Foreign keys are disabled by default. |
| Performance | Works as a B-tree with indices that allow you to get data out of the disk very quickly, which will require fewer disk operations. | The header information is in RAM. Indices can be used to improve performance. Multiple indices can be applied. | Built on the B-tree algorithm. Best suited for small databases; memory requirements grow as the database grows. Avoid using indices on small tables, tables with frequent large batch updates, or columns with many NULL values. |
| Popularity | The most popular | The second most popular | The least popular |
NoSQL Databases for Node.js – Comparison

General
MongoDB
MongoDB is a document-based database management system that does not require a description of the table schema. Considered one of the classic examples of NoSQL systems, it uses JSON-like documents and a database schema. Written in C++.
Many consider MongoDB to be the “default” NoSQL database for Node, since it integrates with the framework very well. But saying it’s always the best choice is a misconception – other NoSQL databases function just as well with proper drivers.
Mongo is also widely used for microservices development. Learn more about building microservices with Node.js in this article.
Redis
Redis is a NoSQL key-value database. Redis stores data in RAM, which is a key feature of this storage. This makes it very fast, but not the most reliable. Periodically, Redis flushes all data to disk, but if the server crashes between adding new information and saving it to disk, the data will be lost. For this reason, Redis is often used not as the main storage, but as a cache, a session management system, or for solving another problem where losing data isn’t a deal-breaker.
Apache Cassandra
Apache Cassandra is a non-relational fault-tolerant distributed DBMS. It was designed to create highly scalable and reliable storage of huge amounts of data presented in the form of a hash. The Java-based project was developed by Facebook in 2008 and was then donated to the Apache Software Foundation in 2009. This DBMS is a hybrid NoSQL solution because it combines a ColumnFamily storage model with the key-value concept.
Data Types
MongoDB
- Integer – store integer values. Depending on the server, it can be either 32-bit or 64-bit;
- Double – store floating-point values;
- Boolean – store boolean (true/false) values;
- String – store character strings. MongoDB uses UTF-8 encoding;
- Arrays – store arrays of values by one key;
- Object – embedded documents;
- Symbol – used in the same way as String, but is usually reserved for languages that use special characters;
- Null – store a Null value;
- Timestamp – store date and time;
- Min/Max – compare values with the largest and smallest BSON (Binary JSON) elements;
- Object ID – store the ID of the document;
- Regular Expression – store regular expressions;
- Code – store JavaScript code in a document;
- Binary data – store binary data;
- Date – store the current date or time in UNIX format.
Redis
- The strings – implemented using the C dynamic string library;
- Lists – linked lists;
- Sets and Hashes – hash tables;
- Ordered sets – skip lists (a special type of balanced tree).
Apache Cassandra
Here, data types are divided into 3 groups:
- built-in data types;
- collections;
- user-created.
Built-in data types:
- ascii – strings (ASCII strings);
- bigint – large integers (64-bit numbers);
- blob – BLOB (bytes);
- Boolean – boolean values (true/false);
- counter – integers (column);
- decimal – integers, floating-point numbers (exact floating-point numbers);
- double – integers (64-bit numbers IEEE-754);
- float – integers, floating point numbers (32-bit numbers IEEE-754);
- inet – strings (IP address, IPv4 or IPv6);
- int – integers (32-bit signed integer);
- text – strings (UTF-8 encoded string);
- timestamp – integers, strings (time);
- timeuuid – unique identifier (UUIDs type 1);
- uuid – unique identifier (UUIDs type 1 or 4);
- varchar – strings (UTF-8 encoded string);
- varint – integers (exact integer).
Collections:
- list – a collection of one or more ordered elements;
- map – a collection of key-value pairs;
- set – collection of one or more elements.
Replication
MongoDB
The storage system in MongoDB represents a replica set. This set has a primary node, and it can also have a set of secondary nodes. All secondary nodes remain intact and are automatically updated when the master node is updated. And if the main node fails for some reason, then one of the secondary nodes becomes the main one.
Redis
Multi-master replication is not supported. Each slave server can act as a master for others. Replication in Redis does not lead to blocking on either the master or the slaves. Write operation is allowed on replicas. When the master and slave servers reconnect after being disconnected, a full synchronization (resync) occurs.
Apache Cassandra
Cassandra storage is designed to handle large amounts of data load between multiple nodes without system failure. Its architecture is based on the fact that system and hardware failures are possible and do occur.
This storage solves the problem of failures by using a decentralized distributed system between homogeneous nodes, where data is distributed among all nodes in the cluster. All nodes on the cluster exchange information every second. Each node’s sequential changelog records writing activity to ensure data longevity.
The data is then indexed and written to a memory element that’s very similar to a write-back cache. When this memory element is full, data is written to disk in an SSTable data file. All records are automatically split and copied across the entire cluster. During the process called compaction, the store periodically merges SSTable files, discarding outdated information and indicators of data deletion.
Indexing
MongoDB
Indexing supports efficient query execution. Without indices, MongoDB needs to scan each document in the collection to select the ones that match the query. This process is extremely inefficient and requires processing a lot of data. To create an index in MongoDB, one has to use the ensureIndex() method.
Redis
Indexing in Redis is quite different from how other databases handle it, so your own use cases and data will determine the best indexing strategy. Here are some general data retrieval strategies besides the simple key/value retrieval:
- sorted sets as indices;
- lexicographic indices;
- geospatial indices;
- IP geolocation;
- full-text search;
- partitioned indices.
Apache Cassandra
Apache Cassandra is a decentralized database that makes a single point of failure by itself. The data is distributed between nodes according to one of the strategies. A common strategy is to distribute data according to the md5 key value – a random partitioner. With the help of this strategy, you don’t need to worry about even data distribution between servers.
To regulate data redundancy, you have to set up the replication factor that defines the total amount of nodes.
A new feature that has been introduced to Cassandra 0.7 is secondary indices. Unlike a regular relational database index, this index is associated with column values, which provides a key to all the rows in the table.
Scalability
MongoDB
MongoDB provides scalability by adding nodes via scripts. After nodes are added, one of the servers becomes the master server, supporting read/write operations, and all other nodes become slaves, used for reading operations. Typically a configuration consists of an odd number of servers. In this case, one server is the main server, the other is the slave, and the third is the arbiter. If the master server fails, the arbiter assigns one of the slave servers to replace it.
Redis
Redis offers a master-slave architecture with a single master or cluster topology. This allows for highly available solutions that deliver consistent performance and reliability. Various vertical and horizontal scaling options are available if you need to adjust the cluster size. As a result, you can grow the cluster according to your needs.
Apache Cassandra
Apache Cassandra has an advantage due to the absence of a central server (Master Node), the failure of which can cause the entire cluster to fail. You can add new nodes to the cluster and update versions of Cassandra on the fly, without additional manual intervention or the reconfiguration of the entire cluster. However, in practice, it is recommended to re-generate keys (tokens) for each node, including the existing ones, in order to maintain the quality of load distribution. The generation of keys for existing nodes can be avoided if there’s a multiple increase in the number of nodes (twice, three times, etc.).
Popularity
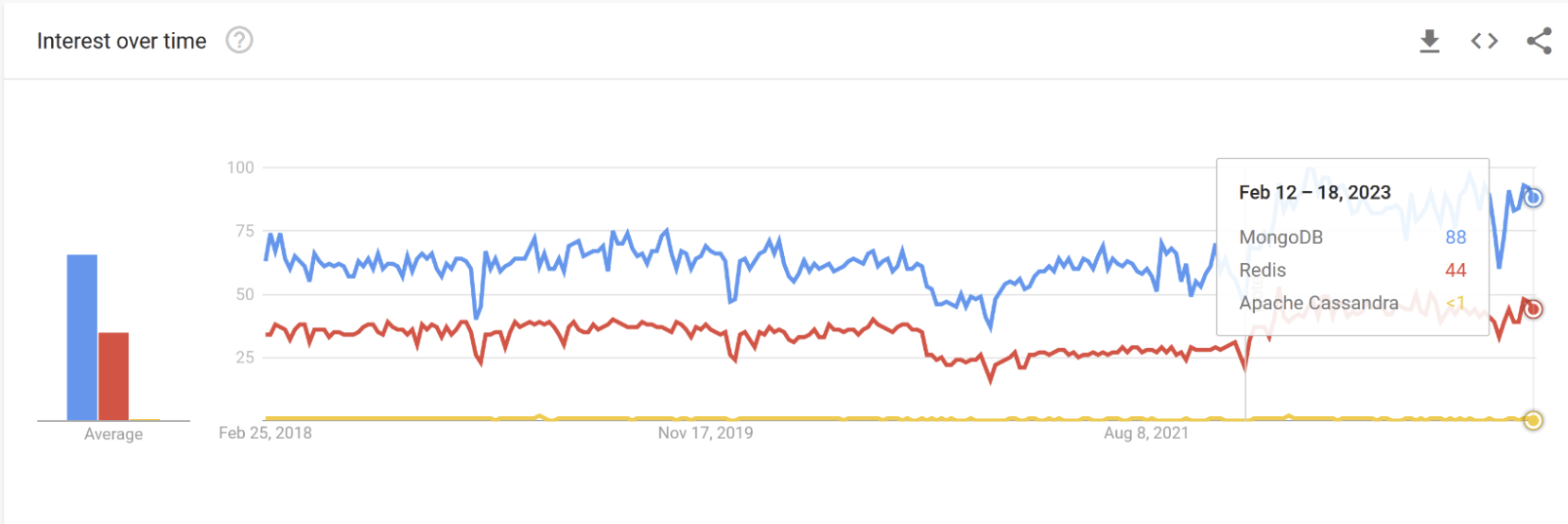
Over the past year, MongoDB was the most popular database of the ones mentioned above. Redis was in second place and Apache Cassandra took the last one.
Choosing the best NoSQL database for Node.js
| Criteria | MongoDB | Redis | Apache Cassandra |
| Data types | Integer, Double, Boolean, String, Arrays, Object, Symbol, Null, Timestamp, Min/Max, Object ID, Regular Expression, Code, Binary data, Date. | The strings, Lists, Sets and Hashes, Ordered sets. | Built-in data types: ascii, bigint, blob, Boolean, counter, decimal, double, float, inet, int, text, timestamp, timeuuid, uuid, varchar, varint. Collections: list, map, set. User-created. |
| Replication | The storage system represents a replica set. It has a primary node, and it can also have a set of secondary nodes. Secondary nodes remain intact, are automatically updated when the master node is updated and can become the main node in case the master node fails. | Multi-master replication is not supported. A slave node can be a master to others. Full synchronization after slave and master reconnection. | The database uses a decentralized distributed system between homogeneous nodes, where data is distributed among all nodes in the cluster. It helps to save data in case of system failure. |
| Indexing | Improves the performance of the database by easing and speeding up the search process. | A user-created strategy of indexing. It varies depending on the use case. | Supports secondary indices. |
| Scalability | Provides scalability by adding nodes via scripts. | Various vertical and horizontal scaling options are available, so you can grow your cluster. | Apache Cassandra has no master node, so you can update it on the fly. |
| Popularity | The most popular | The second most popular | The least popular |
Conclusion
As we wrote at the beginning of the article, the choice of database for a Node.js project depends on the kind of tasks you need to solve. Some developers prefer to use a NoSQL database, some prefer using an SQL one. Nevertheless, that’s just a matter of habit and taste.
This article described SQL and NoSQL database types and gave practical examples for each. If you have doubts about which type of database you should choose for your project, it’s better to collaborate with a reliable development company. Bamboo Agile actively and successfully uses SQL and NoSQL database types in its projects.
Fill out the form on the website to get a free consultation and ensure that the chosen database will perfectly complement your project.





